Agents IA : une nouvelle couche de travail dans les métiers fiduciaires

Quand l'automatisation devient orchestration
En bref. Un agent IA fiduciaire est un module logiciel autonome qui exécute, orchestre et évalue une tâche métier (extraction de données, classification, rapprochement, conseil), tout en sollicitant un humain quand sa confiance descend sous un seuil paramétré. Cet article détaille l'architecture, la gouvernance, et la place de l'humain dans cette nouvelle couche de travail.
Les deux premiers articles de cette série ont posé le cadre : pourquoi Synergix a construit une infrastructure d'intelligence artificielle, et comment cette infrastructure est architecturée. Nous avons décrit des composants, des bases de données, des flux. Mais nous n'avons pas encore abordé ce qui constitue peut-être le changement le plus significatif dans notre manière de travailler : l'émergence d'une nouvelle couche de travail, située entre l'humain et le système, assurée par des agents autonomes.
Cette couche n'existait pas il y a deux ans. Elle s'est constituée progressivement, à mesure que nous avons déployé des agents capables non seulement d'exécuter des tâches, mais de les orchestrer, de les évaluer, et de décider quand solliciter un humain. Ce n'est plus de l'automatisation au sens classique. C'est une forme de délégation structurée, avec des règles, des limites, et une gouvernance.
Cet article décrit cette nouvelle couche : ce qu'elle est techniquement, comment elle s'intègre dans l'organisation du travail, et quelles questions elle soulève.
De l'outil à l'agent : un changement de paradigme
Ce qu'un outil fait
Un outil logiciel classique exécute une fonction définie. Un moteur OCR reçoit une image et produit du texte. Un algorithme de classification reçoit un document et renvoie une catégorie. Un script de rapprochement compare deux listes et identifie les correspondances. Dans chaque cas, la relation est déterministe : entrée, traitement, sortie. L'outil ne décide de rien. Il applique.
Cette approche a ses mérites : prévisibilité, auditabilité, reproductibilité. Elle a aussi ses limites : rigidité face aux cas atypiques, incapacité à gérer l'ambiguïté, nécessité d'une intervention humaine pour chaque exception.
Ce qu'un agent fait
Un agent opère différemment. Il reçoit un objectif plutôt qu'une instruction. Pour atteindre cet objectif, il dispose d'un ensemble de capacités qu'il peut invoquer selon son évaluation de la situation. Il observe les résultats intermédiaires, ajuste sa stratégie, et décide quand il a terminé ou quand il doit escalader.
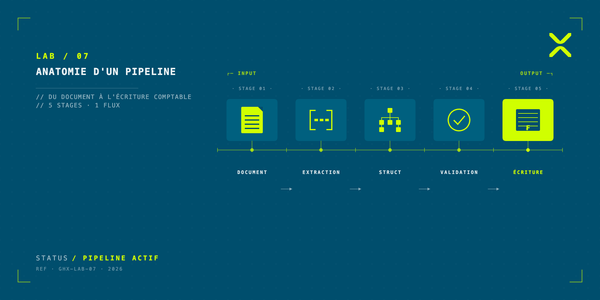
Prenons l'exemple du traitement d'une facture fournisseur. Un pipeline classique enchaînerait les étapes de manière linéaire : OCR, extraction, classification, validation, injection. Si une étape échoue, le document est rejeté.
L'agent documentaire procède autrement. Il examine d'abord le document pour en comprendre la nature : s'agit-il d'une facture unique ou d'un lot à séparer ? Le scan est-il de qualité suffisante ou faut-il demander un renvoi ? Le fournisseur est-il connu ou nouveau ? En fonction de ces évaluations, il adapte son approche. Si l'OCR produit un résultat incertain sur un montant, il peut croiser avec d'autres sources (historique du fournisseur, patterns de facturation). Si une ambiguïté persiste, il formule des hypothèses, les documente, et transmet le dossier préparé à un comptable.
Cette capacité à naviguer dans l'incertitude, à combiner des sources d'information, et à produire un jugement nuancé est ce qui distingue un agent d'un outil.
Architecture technique d'un agent
Nos agents partagent une architecture commune, conçue pour la traçabilité, la modularité et la gouvernance.
Composants structurels
Contexte d'exécution : chaque agent opère dans un contexte qui contient l'ensemble des informations pertinentes pour sa tâche. Pour l'agent documentaire, ce contexte inclut le document source (binaire + métadonnées), l'historique des documents similaires (fournisseur, type, période), les règles spécifiques au client concerné, l'état courant du traitement, et les résultats des étapes précédentes. Le contexte est sérialisé en JSON et versionné à chaque étape.
Registre de capacités : l'agent dispose d'un ensemble de capacités, implémentées comme des services indépendants exposés via API HTTP internes (FastAPI) et coordonnées par un bus d'événements asynchrone (Redis Streams). L'agent documentaire peut invoquer : une cascade OCR multi-moteurs (extraction native via PyMuPDF pour les PDF textuels, PaddleOCR pour les documents structurés avec tables, MinerU pour les scans complexes, chaque moteur étant essayé en fallback selon un seuil de qualité), extraction d'entités via modèle de langage local Qwen3-14B servi par vLLM (avec fallback OpenAI gpt-4o pour les cas complexes), classification supervisée (taxonomie maintenue par les comptables, enrichie continuellement), interrogation des bases métier (Supabase / PostgreSQL pour les référentiels tiers, Qdrant pour la recherche sémantique, Neo4j pour le graphe de connaissance), calcul de score de confiance composite, génération d'écriture comptable via API Business Central, création d'alerte via le système de notification interne.
Moteur de raisonnement : entre l'observation du contexte et l'invocation d'une capacité, l'agent raisonne. Pour les décisions routinières (classification, scoring, détection d'urgence), nous utilisons Qwen3-14B servi en local sur notre infrastructure GPU via vLLM, ce qui garantit zéro fuite de données hors de notre périmètre. Pour les cas complexes nécessitant un raisonnement élaboré, nous appelons OpenAI gpt-4o en mode contrôlé (zero-data-retention activé, scope limité). Cette dualité local-prioritaire / cloud-exception est une décision d'architecture explicite : maximiser le local, minimiser le cloud, n'utiliser le cloud que quand le bénéfice qualité justifie la circulation des données. Le raisonnement est structuré : observation, hypothèses, évaluation des options, décision, justification. Chaque étape est journalisée.
Mémoire de travail : l'agent maintient une mémoire de travail qui persiste pendant la durée de la tâche. Cette mémoire accumule les résultats intermédiaires, les hypothèses formulées, les scores de confiance partiels. Elle permet à l'agent de « revenir en arrière » si une piste s'avère infructueuse.
Mémoire persistante : certains agents disposent également d'une mémoire qui persiste au-delà d'une tâche individuelle. L'agent documentaire accumule des statistiques par fournisseur (formats habituels, montants typiques, taux d'anomalies). Cette mémoire est répartie selon sa nature : les statistiques agrégées et caches courts vivent dans Redis (TTL adaptatif, persistance AOF), les références métier durables sont dans Supabase (PostgreSQL avec Row-Level Security pour l'isolation par client), et les contextes sémantiques (embeddings de documents, historiques de conversations) résident dans Qdrant et Neo4j.
Cycle d'exécution
Le cycle d'exécution d'un agent suit un pattern observe-orient-decide-act (OODA) adapté : observation (l'agent charge le contexte et identifie l'état courant), orientation (il évalue la situation au regard de son objectif et des contraintes), décision (il sélectionne la prochaine action parmi ses capacités), action (il invoque la capacité et récupère le résultat), mise à jour (il enrichit le contexte et itère).
Ce cycle se répète jusqu'à ce que l'agent atteigne son objectif (succès), rencontre une situation qu'il ne peut résoudre (escalade), ou épuise ses tentatives (échec). Chaque itération est journalisée avec timestamp, état du contexte, décision prise, et justification.
Traçabilité intégrale
La traçabilité n'est pas une fonctionnalité ajoutée après coup. Elle est constitutive de l'architecture. Pour chaque document traité, nous conservons : l'historique complet des décisions de l'agent (format JSON, indexé dans notre stack d'observabilité Loki/Grafana), les versions successives du contexte, les appels aux services externes avec requêtes et réponses, le temps de traitement par étape (métriques Prometheus), le résultat final et sa justification.
Cette traçabilité permet l'audit (reconstituer exactement ce qui s'est passé), le debugging (identifier pourquoi un cas a échoué), et l'amélioration continue (analyser les patterns d'erreur).
Confidentialité, audit et conformité : la couche invisible mais structurante
Une architecture d'agents qui manipule des données fiduciaires ne se résume pas à des modèles et des bases. Elle est aussi, et peut-être surtout, un dispositif de protection. Le mandat fiduciaire engage une obligation de fidélité et de diligence (Art 398 CO). Ce devoir de discrétion, renforcé par les clauses de confidentialité signées avec chaque mandant, s'applique à tout ce qui transite par nos systèmes. La nLPD ajoute une responsabilité de sous-traitant ; le RGPD s'applique pour nos clients européens. Plusieurs de nos clients sont par ailleurs régulés par la FINMA, et même sans être nous-mêmes sous régulation directe, nous devons concevoir notre traitement de la donnée pour répondre aux exigences de gouvernance des sous-traitants que ces régulations imposent à nos clients : traçabilité, isolation, possibilité d'audit. Tous ces cadres convergent vers une exigence simple à formuler et exigeante à tenir, la donnée client ne quitte notre périmètre qu'avec une justification fonctionnelle explicite, et chaque circulation est tracée, auditable, réversible.
Cette exigence façonne notre architecture autant que les choix techniques. Elle constitue ce que nous appelons en interne « la couche invisible » : invisible au comptable qui utilise les agents, invisible au client qui reçoit ses bilans, mais structurellement présente dans chaque appel, chaque log, chaque écriture.
Le principe : masquer avant d'envoyer
La règle par défaut est simple : toute donnée qui sort de la frontière de confiance Synergix vers un fournisseur LLM tiers (OpenAI principalement, demain Anthropic ou autres) passe par notre pipeline de masquage de PII (informations personnelles identifiables). Le masquage est fait par GLiNER, un détecteur d'entités nommées multilingue (français, allemand, anglais, les trois langues que nous traitons) déployé en local. Il identifie les noms de personnes physiques, identifiants nationaux (AVS), adresses, IBAN personnels, dates de naissance, et autres signaux PII définis dans notre politique interne. Chaque entité détectée est remplacée par un jeton anonyme avant l'appel LLM ; le mapping de substitution reste exclusivement en mémoire processus, jamais persisté, jamais loggé. La réponse du LLM est ensuite « démasquée » côté Synergix avant d'être consommée.
En cas d'échec du masqueur, la règle est intransigeante : la requête échoue plutôt que de partir non masquée. C'est le principe du fail-closed. Une exception silencieuse aurait été pire qu'un appel qui échoue.
La carve-out matrix : quand l'utile prime, mais sous conditions
Tous les pipelines ne peuvent pas être masquées intégralement. L'extraction d'une facture fournisseur a besoin du nom du fournisseur, de son adresse, des montants nominatifs : ce sont les données qui constituent la facture elle-même. Les masquer rendrait l'extraction inutile.
Nous avons donc défini explicitement une matrice de carve-outs, ratifiée au niveau direction : seules certaines pipelines (traitement factures fournisseurs et débiteurs, parsing relevés bancaires) sont autorisées à appeler un LLM avec des données non masquées. Cette autorisation n'est pas un blanc-seing ; elle est compensée par des contrôles renforcés.
Audit renforcé sur les pipelines avec carve-out
Pour chaque appel LLM dans un pipeline carve-out :
- Entrée d'audit obligatoire : identifiant de corrélation, raison sociale du client, identifiant de pipeline, fournisseur LLM, modèle, taille du prompt et de la réponse, horodatage UTC, code de finalité (par exemple invoice_extraction_v1).
- Aucun corps de prompt en log (cela défierait l'objet du masquage), mais une empreinte SHA-256 du prompt est conservée pour non-répudiation.
- Échantillonnage : 1 % des appels carve-out ont leur prompt et réponse complets stockés dans une table dédiée chiffrée par enregistrement, séparée du log courant. Cela permet la reconstruction forensique en cas d'incident sans transformer le log courant en surface de fuite.
- Rétention : au moins 10 ans, alignée sur l'obligation d'archivage comptable (Art 958f CO) et compatible avec les exigences que la régulation FINMA impose à ceux de nos clients qui en relèvent.
- Alerte d'anomalie : un volume de carve-out qui dépasse trois fois la médiane glissante sur 7 jours dans une fenêtre d'une heure déclenche automatiquement une alerte au responsable sécurité (signal de dérive de configuration ou d'usage anormal).
Sur les LLMs cloud que nous utilisons, le mode zero-data-retention (ZDR) est systématiquement activé : les données envoyées ne sont ni stockées, ni utilisées pour entraîner les modèles du fournisseur, ni accessibles à ses équipes humaines. C'est une condition contractuelle non négociable.
Isolation par client : la cloison étanche
Multi-tenancy ne signifie pas seulement « plusieurs clients sur la même infrastructure ». Cela signifie que la donnée d'un client ne doit jamais être accessible, même par accident, même par bug, depuis le contexte d'un autre client.
L'isolation est appliquée à chaque couche :
- Supabase / PostgreSQL : Row-Level Security (RLS) systématique sur toutes les tables contenant des données client. Les politiques d'accès sont définies au niveau du moteur de base de données, pas au niveau applicatif, ce qui rend le contournement structurellement impossible.
- Qdrant (recherche sémantique) : chaque vecteur porte dans son payload l'identifiant du client propriétaire, et toute requête est filtrée en amont par cet identifiant. Les collections de takeover sont par ailleurs entièrement séparées, une par dossier, ce qui élimine toute possibilité de fuite inter-dossiers.
- Neo4j (graphe de connaissance) : les sous-graphes par client sont marqués au niveau des nœuds et arêtes, et les requêtes Cypher sont systématiquement filtrées par cet identifiant.
- MinIO (stockage objet) : préfixes de chemin par client (
{client_shortname}/...), avec contrôle d'accès au niveau bucket.
Quand un nouveau collaborateur Synergix rejoint l'équipe, il reçoit l'accès aux clients dont il s'occupe, pas plus. L'isolation technique sous-tend l'isolation organisationnelle.
Défense en profondeur : containers, secrets, surface
Au-delà de la couche données, l'infrastructure elle-même applique le principe de moindre privilège.
Hardening des containers : chaque service Docker démarre avec cap_drop: ALL (toutes les capacités Linux retirées) et security_opt: no-new-privileges (interdiction d'élever les droits en cours d'exécution). Les services qui ont besoin d'une capacité spécifique la déclarent explicitement, dans une matrice tenue à jour et auditée. Aucun service ne tourne avec le drapeau privileged. Cette discipline rend l'éventuelle compromission d'un container significativement moins exploitable comme tremplin vers l'hôte.
Secrets : aucun secret en clair dans le code, ni dans les variables d'environnement publiées. Tous les secrets transitent par notre coffre-fort Infisical, accessibles uniquement aux services qui en ont besoin, et rotables sans redéploiement.
Logs : la même politique de masquage qui s'applique aux LLMs s'applique aux logs. Loki et GlitchTip reçoivent des entrées dont les PII ont été stripées, parce que les logs sont durables, requêtables, et accessibles à plus de personnes qu'une base de production.
Le droit à l'effacement et la procédure d'effacement multi-stores
L'Art 17 du RGPD et l'art. 32 al. 2 nLPD donnent à toute personne le droit de demander l'effacement de ses données. Honorer ce droit dans une architecture multi-stores n'est pas trivial : il faut effacer dans Supabase, dans Qdrant, dans Neo4j, dans Mem0, dans MinIO, dans Redis, dans les logs Loki, dans les traces Langfuse, dans les événements GlitchTip, dans Outline, et propager la demande aux sous-processeurs externes.
Nous avons formalisé une procédure cross-stores qui orchestre ces effacements dans un ordre garanti, avec contrôle d'achèvement par store et émission d'une attestation d'effacement pour la personne concernée. Quand une obligation de rétention prime (Art 958f CO pour les pièces comptables 10 ans, exigences contractuelles imposées par certains de nos clients régulés FINMA sur les pistes d'audit), la procédure bascule en restriction plutôt qu'en effacement : l'enregistrement est conservé mais marqué bloqué, retiré des accès actifs, et un refus partiel motivé est communiqué au demandeur.
Cette procédure n'est pas un document d'étagère. Elle est exécutée à chaque demande, mesurée dans son temps de réponse (objectif : sous 30 jours, conforme RGPD), et révisée à chaque évolution de l'architecture.
Ancrages réglementaires
L'ensemble du dispositif s'inscrit dans un référentiel réglementaire et contractuel que nous documentons explicitement et révisons en continu :
- Art 398 CO (devoir de fidélité et de diligence du mandataire) : socle du mandat fiduciaire, qui fonde le devoir de discrétion sur l'ensemble des données client.
- Clauses de confidentialité contractuelles signées avec chaque mandant : extension explicite du devoir de fidélité, opposable et auditable.
- nLPD (loi suisse sur la protection des données, en vigueur depuis 2023) : principes de finalité, transparence, sécurité, transferts internationaux, responsabilité de sous-traitant.
- RGPD : pour nos clients ou employés résidant dans l'UE.
- Art 958f CO : durée de conservation des pièces comptables (10 ans), avec garantie d'intégrité et de restitution, qui prime sur le droit à l'effacement pour ces enregistrements.
- Exigences clients régulés FINMA : certains de nos clients sont sous régulation FINMA. Sans être nous-mêmes régulés, nous concevons notre traitement de la donnée pour répondre aux exigences de gouvernance des sous-traitants que ces régulations imposent à ces clients (traçabilité, isolation, possibilité d'audit).
- OWASP LLM Top 10 : référentiel sécuritaire spécifique aux applications LLM, que nous suivons pour la conception et la revue de chaque nouveau pipeline.
Cette architecture de conformité n'est pas un coût. C'est une condition d'existence. Une fiduciaire qui ne peut pas démontrer la confidentialité de son traitement n'a pas de clients. Une plateforme IA qui ne peut pas isoler ses tenants n'est pas une plateforme professionnelle. Nous traitons cette exigence comme une exigence de premier plan, pas comme une formalité tardive.
Les agents déployés
Plusieurs agents sont actuellement en production. Chacun a un périmètre défini, des capacités propres, et des métriques de performance suivies.
Agent documentaire
Périmètre : traitement de l'ensemble des documents entrants (factures fournisseurs, factures débiteurs, relevés bancaires ISO 20022, scans multi-pages, documents récupérés via connecteurs fournisseurs).
Capacités : prétraitement (détection MIME, décompression, segmentation par ruptures sémantiques), OCR en cascade adaptative (extraction native pour PDF textuels, PaddleOCR pour documents structurés avec tables, MinerU pour scans complexes, fallback automatique selon la qualité observée), extraction d'entités structurées (fournisseur, montants HT/TTC/TVA avec validation arithmétique croisée, dates, références, IBAN), classification supervisée selon notre taxonomie interne, scoring composite multi-dimensions (qualité OCR, complétude des champs, cohérence interne, conformité historique fournisseur, plausibilité du montant), injection ERP via API transactionnelle Business Central.
Métriques : en production, l'agent documentaire traite l'ordre du millier de documents par mois pour notre portefeuille actuel, avec un objectif de taux d'automatisation supérieur à 80 % et un temps de traitement médian de l'ordre de la dizaine de secondes par document. Ces métriques sont monitorées en continu et publiées dans nos rapports de performance internes. Le seuil d'escalade est paramétré par client et par type de document, recalibré périodiquement à partir des cas litigieux.
Agent comptable
Périmètre : validation des écritures générées par l'agent documentaire, rapprochement écritures-pièces, détection d'anomalies, contrôles de cohérence.
Capacités : matching multi-critères sur le grand livre (correspondances exactes, tolérances paramétrées, heuristiques historiques), validation des imputations analytiques (centres de coût, projets, entités légales), détection proactive d'anomalies (écritures orphelines, soldes inhabituels, variations de comportement fournisseur), génération d'alertes qualifiées.
Métriques : objectif de taux de validation automatique supérieur à 90 % des écritures proposées, temps de traitement de l'ordre de quelques secondes par écriture. Plusieurs alertes d'anomalie qualifiées sont générées chaque semaine et revues par l'équipe comptable. L'agent comptable ne génère pas d'écritures, il les valide ou les conteste. Cette séparation des responsabilités est délibérée.
Agent de prospection
Périmètre : veille sur le registre du commerce suisse, qualification de leads, génération de fiches prospects.
Capacités : interrogation quotidienne du registre du commerce (API Zefix), extraction des événements pertinents (créations, modifications de raison sociale, changements d'adresse dans le canton de Genève), enrichissement via sources publiques, scoring des prospects selon critères prédéfinis (secteur, taille estimée, signaux de besoin fiduciaire), génération de fiches structurées pour l'équipe commerciale.
Métriques : plusieurs centaines d'événements analysés par semaine, plusieurs dizaines de leads qualifiés transmis. Cet agent opère en mode autonome complet (pas d'impact sur les données comptables).
Agent conversationnel
Périmètre : interface entre les collaborateurs et la base de connaissances interne.
Capacités : recherche sémantique sur base vectorielle (Qdrant, plusieurs collections indexées en HNSW, embeddings denses haute dimension), formulation de réponses contextualisées via architecture RAG combinée à un graphe de connaissance Neo4j, citation systématique des sources, apprentissage des lacunes documentaires (les questions sans réponse satisfaisante deviennent des candidats pour enrichir le corpus).
Métriques : temps de réponse de l'ordre de quelques secondes, retours utilisateurs très majoritairement positifs (mesurés par feedback explicite après chaque échange). Fonction secondaire : capitalisation du savoir métier, les questions posées et les réponses jugées utiles enrichissent progressivement le corpus de connaissances structuré.
Orchestration et coordination
Les agents ne travaillent pas en silos. Leur coordination est assurée par une couche d'orchestration dédiée.
L'orchestrateur
L'orchestrateur n'est pas un agent au sens défini précédemment. Il ne raisonne pas sur des objectifs métier. C'est un composant d'infrastructure (un autoscaler Python qui combine la loi de Little pour le dimensionnement déterministe et un prédicteur de charge basé sur Prophet pour anticiper les pics) qui gère les flux, les priorités, et les transitions. Il est déployé en redondance sur notre cluster Docker, supervise l'ensemble des workers, et garantit qu'aucune tâche n'est perdue ni dupliquée.
Machine à états : chaque tâche en cours est représentée dans Supabase (table script_executions) avec un statut explicite (queued, running, completed, failed, blocked) et un historique de transitions. Les transitions sont atomiques et auditées.
Gestion des priorités : les tâches sont priorisées selon des règles configurables. Les documents urgents (clôture imminente, client prioritaire) passent devant. Les règles de priorité sont versionnées en configuration et peuvent être modifiées sans redéploiement.
Bus d'événements : la communication entre l'orchestrateur et les agents passe par Redis Streams, configuré avec consumer groups pour la garantie de livraison at-least-once, persistance, et capacité de rejeu en cas d'échec. Les événements importants (création d'écriture comptable, escalade vers un comptable, détection d'anomalie) transitent également par ce bus pour permettre à plusieurs services de réagir indépendamment.
Protocoles de communication
Les agents communiquent via des messages structurés dont le schéma est validé (modèles Pydantic + JSON Schema). Un message de sortie de l'agent documentaire contient : identifiant unique de la tâche, statut (succès, échec, escalade), données extraites (structure normalisée), score de confiance composite et scores partiels, métadonnées de traçabilité (durée, version des modèles, nombre d'itérations), et en cas d'escalade : hypothèses formulées, points de doute, suggestions de résolution.
Gestion des échecs
Les échecs sont traités de manière différenciée selon leur nature.
- Échec technique (service indisponible, timeout) : retry automatique avec backoff exponentiel, plafonné à un nombre limité de tentatives.
- Échec métier (document illisible, format inconnu) : escalade immédiate vers un opérateur humain avec contexte complet.
- Échec de confiance (score insuffisant) : escalade avec dossier préparé.
Gouvernance de l'autonomie
La question centrale du déploiement d'agents est celle de l'autonomie. Combien de latitude leur accorder ? Comment encadrer cette latitude ?
Niveaux d'autonomie
Nous avons défini quatre niveaux, du plus contraint au plus libre.
- Niveau 1. exécution supervisée : l'agent propose, l'humain valide avant exécution. Utilisé pour les nouveaux types de documents, les nouveaux clients, ou après un incident.
- Niveau 2. exécution conditionnelle : l'agent exécute si son score de confiance dépasse un seuil prédéfini, escalade sinon. C'est le mode standard pour le traitement documentaire courant.
- Niveau 3. exécution auditée : l'agent exécute sans validation préalable, mais ses actions sont auditées a posteriori par échantillonnage.
- Niveau 4. exécution autonome : l'agent opère sans supervision directe. Réservé aux tâches sans impact sur les données comptables.
Calibration des seuils
Les seuils ne sont pas arbitraires. Ils résultent d'une analyse statistique de la corrélation entre score prédit et taux de validation humaine. Pendant la phase initiale, tous les documents ont été traités en mode supervisé. Une fois suffisamment de cas accumulés, nous avons tracé la courbe de calibration pour identifier le seuil au-delà duquel le taux de validation humaine devient suffisamment élevé pour basculer en exécution conditionnelle. Les seuils sont révisés trimestriellement en fonction des dérives observées.
Garde-fous techniques
- Limites de périmètre : chaque agent a un périmètre d'action défini au niveau de ses capacités. L'agent documentaire peut créer des écritures, pas les supprimer.
- Limites de volume : des quotas empêchent les comportements anormaux. Si un agent tente d'injecter plusieurs fois la moyenne attendue d'écritures par heure, une alerte se déclenche automatiquement.
- Limites de montant : une facture dépassant un seuil défini par client passe systématiquement par un comptable, quel que soit le score de confiance.
- Cohérence transactionnelle : les opérations critiques sont groupées en transactions atomiques. Si une partie échoue, l'ensemble est annulé.
Une nouvelle couche dans l'organisation du travail
L'introduction des agents modifie la structure du travail fiduciaire. Cette modification n'est pas une substitution mais une réorganisation.
Avant : flux linéaires
Dans l'organisation traditionnelle, le travail documentaire suivait un flux linéaire. Le document arrive, un comptable l'ouvre, l'analyse, saisit les informations, vérifie, valide. Le temps du comptable est consommé sur chaque document, indépendamment de sa complexité.
Maintenant : flux stratifiés
Avec les agents, le flux devient stratifié. La majorité des documents traversent la couche agent sans intervention humaine. Les comptables se concentrent sur les cas qui nécessitent leur expertise : cas ambigus, nouveaux fournisseurs, montants exceptionnels, situations atypiques.
Cette stratification a plusieurs effets.
Recentrage sur l'expertise : le temps libéré sur les tâches routinières est réinvesti dans l'analyse, le conseil, la relation client. Le comptable qui traitait des dizaines de factures par jour se concentre désormais sur les plus complexes et consacre le reste de son temps à des activités à plus forte valeur.
Émergence de nouvelles compétences : la supervision des agents devient une compétence professionnelle. Savoir interpréter les alertes, calibrer les seuils, identifier les angles morts, améliorer les règles.
Modification des pics de charge : les périodes de clôture restent intenses, mais différemment. Le volume documentaire est absorbé par les agents. La charge humaine se concentre sur la validation des cas limites.
La question du contrôle
Une inquiétude légitime accompagne cette évolution : perd-on le contrôle ? La réponse est non, mais à condition d'avoir conçu le système pour le maintenir. Le contrôle se manifeste à plusieurs niveaux : en amont par la définition des règles et des limites, en temps réel par le monitoring et les alertes, en aval par l'audit et l'analyse.
Le contrôle n'est pas l'intervention systématique. C'est la capacité d'intervenir quand c'est nécessaire, avec l'information suffisante pour le faire efficacement.
Ce que nous avons appris
Plusieurs mois de production ont fait émerger des observations que nous n'avions pas anticipées.
Les agents développent des « habitudes » : pas au sens d'un apprentissage autonome, mais au sens d'une accumulation de contexte qui influence leurs décisions. L'agent documentaire « connaît » désormais les particularités de nos principaux fournisseurs.
Les agents révèlent des patterns invisibles : l'agent comptable a identifié des anomalies que nous n'aurions pas détectées manuellement. Ces signaux faibles, invisibles à l'échelle d'une facture individuelle, deviennent visibles quand un agent agrège des milliers de cas.
Les agents ont des angles morts : un agent confiant dans un pattern peut manquer une exception. Nous avons eu un cas où l'agent documentaire a systématiquement mal classé les avoirs d'un nouveau fournisseur pendant deux semaines. La supervision humaine reste indispensable.
L'escalade bien conçue crée de la valeur : quand un agent escalade avec ses hypothèses et suggestions, le comptable peut souvent trancher en quelques secondes. L'escalade n'est pas un échec, c'est une collaboration efficace.
La place du professionnel
Je termine sur ce point parce qu'il est central et parce qu'il est souvent mal compris.
L'introduction d'agents dans le travail fiduciaire ne réduit pas le rôle du professionnel. Elle le recentre. Le comptable qui supervisait des saisies supervise désormais des agents. Il définit les règles, calibre les seuils, analyse les exceptions, améliore les processus. Son expertise n'est plus consommée sur des tâches répétitives : elle est mobilisée sur des décisions qui comptent.
La relation client n'est pas affectée. Un dirigeant inquiet pour la trésorerie de son entreprise ne parle pas à un agent. Il parle à un professionnel qui connaît son dossier, comprend son contexte, et peut lui apporter un conseil adapté. Cette dimension relationnelle, faite d'écoute, de présence et de jugement, reste profondément humaine.
La responsabilité professionnelle demeure entière. Quand un comptable valide un bilan, il engage son nom et sa réputation. L'agent a préparé le terrain, structuré l'information, signalé les anomalies. Mais la signature reste humaine, et avec elle la responsabilité.
Les agents que nous avons déployés constituent une nouvelle couche de travail. Pas une couche de substitution, mais une couche de préparation, de structuration, de filtrage. Une couche qui permet aux professionnels de consacrer leur attention à ce qui la mérite vraiment.
Glossaire
Agent IA. Module logiciel autonome qui exécute une tâche métier (extraction, classification, rapprochement, conseil) en mobilisant un modèle de langage et un contexte structuré, et qui peut décider lui-même de solliciter un humain quand sa confiance descend sous un seuil paramétré.
Carve-out matrix. Matrice de cas d'usage où l'envoi de données vers un fournisseur de modèle externe (par exemple gpt-4o sous masquage) est explicitement autorisé, après ratification par la direction et avec audit renforcé. Tout ce qui n'est pas dans la matrice reste interdit par défaut (principe fail-closed).
Escalade. Décision automatique d'un agent de passer la main à un humain quand son score de confiance, sa vérification arithmétique ou sa cohérence inter-référentiels passe sous un seuil. L'escalade n'est pas un échec : c'est une collaboration efficace.
Fail-closed. Principe de sécurité qui consiste à interdire par défaut tout traitement non explicitement autorisé. À l'inverse du fail-open, ce mode privilégie la conformité au débit.
RLS (Row-Level Security). Mécanisme PostgreSQL/Supabase qui garantit qu'un utilisateur authentifié ne peut accéder qu'aux lignes de table qui lui sont explicitement attribuées. Garantit l'isolation des données entre clients dans une base partagée.
Seuil de confiance. Valeur numérique (entre 0 et 1) en dessous de laquelle l'agent escalade vers un humain plutôt que d'auto-valider. Calibré par cas d'usage et ajustable selon les retours d'expérience.
Questions fréquentes
(Section à reprendre en JSON-LD FAQPage au moment de la mise en ligne pour signal Google AI Overviews et reprise par les moteurs LLM.)
Qu'est-ce qu'un agent IA fiduciaire ?
Un agent IA fiduciaire est un module logiciel autonome qui exécute une tâche métier (extraction de données, classification documentaire, rapprochement comptable, conseil) en mobilisant un modèle de langage et un contexte structuré, sous la gouvernance d'une fiduciaire. Il peut décider lui-même de solliciter un humain quand sa confiance descend sous un seuil paramétré.
Quelle différence entre un outil et un agent ?
Un outil exécute une fonction définie de façon déterministe : entrée, traitement, sortie. Un agent ajoute trois capacités : il peut orchestrer plusieurs étapes, évaluer la qualité de son propre résultat, et décider de solliciter un humain quand l'incertitude le justifie. L'agent gère l'ambiguïté ; l'outil ne le peut pas.
Comment une fiduciaire garantit-elle le devoir de discrétion avec un LLM ?
Trois leviers cumulatifs : (1) servir les modèles localement par défaut (Qwen3-14B sur infrastructure interne) pour éviter toute sortie de données ; (2) appliquer un pipeline de masquage des données personnelles (GLiNER multilingue) avant tout envoi externe ; (3) restreindre les usages d'un modèle cloud à une matrice de cas d'usage ratifiée par la direction (carve-out matrix), avec audit renforcé. Le principe directeur est fail-closed : par défaut, rien ne sort. Le fondement juridique combine le devoir de fidélité du mandataire (Art 398 CO), les clauses de confidentialité contractuelles, et la nLPD comme responsabilité de sous-traitant.
Qu'est-ce que la carve-out matrix ?
C'est la matrice qui définit, cas d'usage par cas d'usage, les conditions exactes dans lesquelles l'envoi de données vers un modèle externe est autorisé. Elle est ratifiée par la direction et révisée à fréquence trimestrielle. Tout cas qui n'y figure pas est interdit par défaut. Cette discipline est ce qui permet de cumuler la qualité de gpt-4o sur certains cas et la conformité au devoir de discrétion fiduciaire (Art 398 CO + clauses contractuelles + nLPD) sur l'ensemble du périmètre.
Quand un agent escalade-t-il vers un humain ?
Plusieurs déclencheurs cumulatifs : un score de confiance global sous le seuil paramétré, une vérification arithmétique qui échoue (HT + TVA ≠ TTC), une incohérence inter-référentiels (le fournisseur n'existe pas dans la base, le pattern historique diffère), un cas explicitement marqué comme nécessitant une validation humaine (montant supérieur à un seuil, premier traitement d'un nouveau client). L'escalade n'est pas un échec. C'est la conception qui garantit que les cas qui méritent un regard humain en reçoivent un.