Comment notre infrastructure IA est architecturée
Panorama d'une stack interne, des modèles à l'observabilité.*
Pourquoi ce panorama avant les approfondissements
Dans l'article précédent, nous avons raconté pourquoi nous avions choisi de construire une infrastructure IA en interne plutôt que de souscrire à un service clé en main. La conclusion tenait en trois critères : souveraineté de la donnée, coût marginal maîtrisé, apprentissage stratégique. Le « pourquoi » est posé. Il est temps de décrire le « comment ».
Cet article ne plonge dans aucun composant en détail. Il dresse une vue d'ensemble, couche par couche, qui prépare les approfondissements à venir. Une infrastructure IA opérationnelle ressemble moins à un produit cohérent qu'à un alignement de couches indépendantes, chacune avec ses contraintes, son cycle de vie, et ses arbitrages propres. Comprendre la stack avant de plonger dans une couche permet de garder en tête où l'on est.
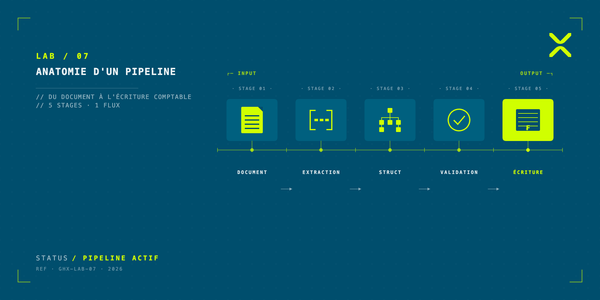
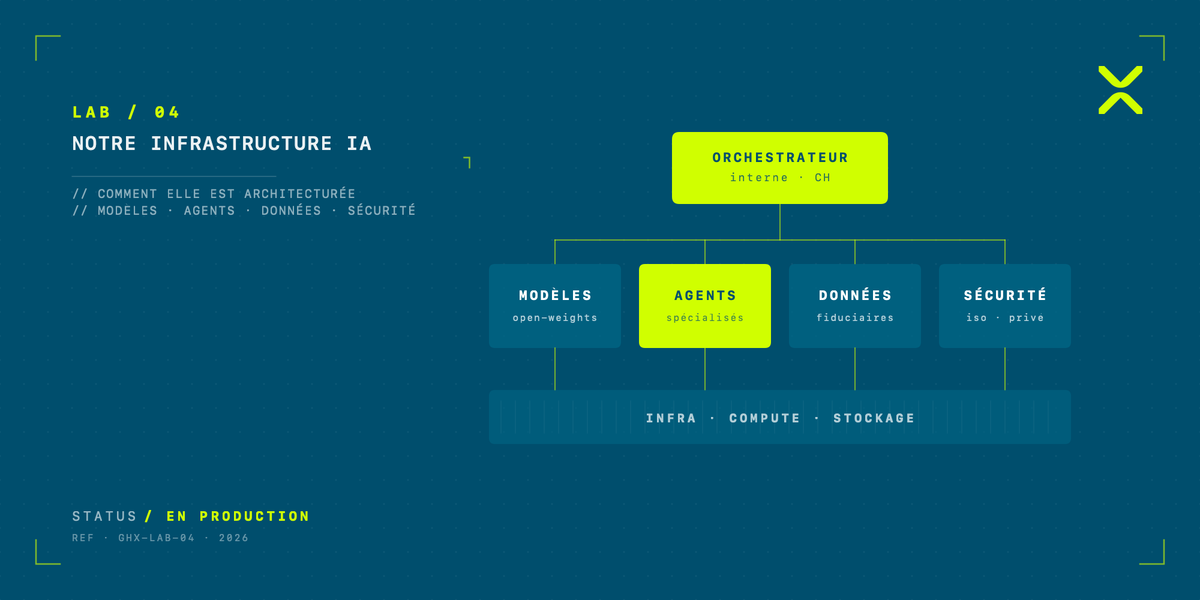
Cinq couches, un fil conducteur
Notre stack se laisse lire comme cinq couches empilées, des données vers les usages :
- Stockage : où vivent les données et sous quelle forme.
- Modèles : qui répond aux questions et avec quelles garanties.
- Orchestration : qui décide quoi est exécuté, dans quel ordre, par quel composant.
- Agents et services métier : la logique qui produit la valeur visible côté comptable.
- Observabilité et gouvernance : la couche transversale qui voit tout, journalise tout, déclenche les alertes.
Chaque couche a été construite avec un principe directeur : la donnée client ne quitte pas notre périmètre par défaut. Toute exception est encadrée, ratifiée, tracée.
Couche 1 : stockage
La diversité des usages impose une diversité de stores. Vouloir tout faire avec un seul moteur est une fausse économie. Nous combinons quatre stores spécialisés, chacun retenu pour ce qu'il fait mieux que les autres.
Supabase / PostgreSQL est le référentiel transactionnel. Il accueille les entités métier (clients, fournisseurs, factures, écritures comptables, plans comptables), les utilisateurs, les rôles, et la configuration applicative. Nous y exploitons la Row-Level Security (RLS) sur les tables qui contiennent des données client, pour garantir l'isolation par client. La généralisation aux tables techniques restantes
est en cours dans le sprint en cours. L'isolation n'est pas applicative, elle est posée au niveau de la base. Cela change la conversation avec un auditeur.
Qdrant est notre base vectorielle. Elle accueille les embeddings des documents (factures, contrats, courriers, mais aussi notes de réunion et entrées de base de connaissance). Les embeddings sont produits par un modèle local d'embedding multilingue. Le choix de Qdrant tient à trois propriétés : performance sur des collections de plusieurs millions de vecteurs, support natif du payload filter (qui permet de combiner similarité sémantique et filtres exacts, par exemple « factures du client X dans la dernière année »), et déploiement on-premise simple.
Neo4j est notre graphe de connaissance. Il modélise les relations entre entités : un fournisseur facture plusieurs clients, un dossier contient plusieurs documents, un document a un type, une date, un montant. Là où Qdrant excelle dans la similarité, Neo4j excelle dans le parcours typé : « tous les documents reçus de ce fournisseur dans les six derniers mois, regroupés par type ». L'article #10 reviendra sur la combinaison Qdrant + Neo4j.
Redis sert de couche de cache court et de bus d'événements asynchrone. Les caches courts (résultats d'OCR récents, résolutions de référentiels, scores temporaires d'agents) y vivent avec un TTL adaptatif. Le bus Redis Streams transporte les messages entre agents et services, avec consumer groups pour garantir une livraison à au moins un consommateur.
MinIO complète l'ensemble pour le stockage objet : binaires des documents originaux, scans, exports, archives. Compatible API S3, déployable on-premise, il évite la dépendance à un cloud propriétaire pour l'archivage long terme.
Quatre stores, quatre rôles, quatre contrats. La donnée client est dans Supabase + Qdrant + Neo4j + MinIO. Aucune ne sort.
Couche 2 : modèles
Servir un modèle de langage en local est une décision d'architecture qui se mesure au moins à six critères : qualité de raisonnement, qualité multi-langue, latence, coût par requête, contraintes opérationnelles (charge GPU, mises à jour), et couverture des usages. Nous avons fait converger nos choix sur une architecture local-prioritaire avec exception cloud encadrée.
Qwen3-14B est notre modèle local par défaut. Il est servi par vLLM, un moteur d'inférence haute performance qui pratique le PagedAttention et la batched inference. Notre cluster GPU on-premise, dimensionné pour notre charge, sert ce modèle à une latence cible de moins de deux secondes pour 90 % des requêtes en conditions nominales. Qwen3-14B est servi par un moteur d'inférence haute performance qui optimise l'empreinte mémoire sans dégrader sensiblement la qualité sur nos tâches.
OpenAI gpt-4o intervient en exception encadrée pour les cas où la qualité de raisonnement justifie la circulation de données. Toute requête vers gpt-4o passe par notre pipeline de masquage de PII (article #6 dédié), avec mode zero-data-retention activé contractuellement et journalisation systématique. Nous traitons par cette voie environ 8 % du volume total, principalement les cas atypiques détectés par les agents.
Un modèle d'embedding multilingue, plus petit, sert localement les besoins de représentation vectorielle. Il est stable, économique, et ne nécessite pas de mise à jour fréquente.
La couche modèles expose une API interne unifiée. Un agent qui demande une complétion ne sait pas, de son point de vue, si la requête est routée vers Qwen ou gpt-4o. La décision de routage se prend dans une couche d'orchestration en fonction de critères explicites (sensibilité, complexité, coût). C'est cette indirection qui nous permet d'opérer la dualité local-prioritaire / cloud-exception sans complexifier le code des agents.
Couche 3 : orchestration
L'orchestration est la couche qui répond à la question « qui décide quoi ». Elle est doublement stratégique. D'abord parce que c'est elle qui rend l'architecture observable : un système où un LLM décide de tout n'est ni auditable ni reproductible. Ensuite parce que c'est elle qui contrôle le coût : un appel à un modèle est une dépense, et une orchestration qui en multiplie les invocations sans nécessité ronge la rentabilité de l'infrastructure.
Notre orchestration repose sur trois primitives.
Un bus d'événements asynchrone (Redis Streams avec consumer groups) transporte les messages entre composants. Chaque message contient un identifiant, un type d'événement, le contexte sérialisé en JSON, et une signature. Les consommateurs s'abonnent aux types qui les intéressent et émettent en retour des événements de réponse. Cette architecture événementielle a deux vertus : elle découple les composants (un service peut évoluer sans casser ses voisins) et elle absorbe les pics de charge (une queue qui se remplit n'écrase pas les services en aval).
Un autoscaler Python ajuste en continu le nombre d'instances actives par service en fonction de la charge observée et prédite. Il combine la loi de Little (le nombre d'instances nécessaire est le produit du débit et de la latence cible) et un prédicteur Prophet entraîné sur l'historique journalier. Cette double approche évite à la fois la sous-allocation (qui dégrade la latence) et la sur-allocation (qui gaspille le GPU).
Une logique de routage déterministe décide, pour chaque requête de complétion, si elle est traitée en local (Qwen3) ou en exception encadrée (gpt-4o). Le routage repose sur cinq critères : sensibilité de la donnée (PII détectée ou non), complexité estimée de la tâche (longueur du prompt, type d'opération), historique des échecs sur tâches similaires, taux de saturation actuel du local, et budget alloué au cloud sur la fenêtre courante. Le résultat est une décision binaire, journalisée, vérifiable.
Cette couche est délibérément non-LLM. Ce n'est pas un agent qui décide quel agent fait quoi. C'est une mécanique explicite, avec règles documentées, qui rend l'ensemble auditable. Le ratio que nous appliquons est connu : 80 % de logique déterministe, 20 % de décisions IA.
Couche 4 : agents et services métier
Les agents constituent la couche visible du système. Chacun encapsule un objectif métier, un ensemble de capacités, un cycle d'exécution observe-orient-decide-act, et une mémoire (de travail et persistante). L'article #5 décrit cette couche en détail. Pour ce panorama, on retient quatre agents en production :
- L'agent documentaire traite les factures fournisseurs, les contrats reçus, les courriers entrants. Il enchaîne l'extraction OCR, l'extraction d'entités, la classification, et la décision automate vs escalade.
- L'agent comptable propose les écritures à partir des données extraites. Il interroge le plan comptable du client, applique les règles internes, et soumet la proposition au comptable humain pour validation.
- L'agent de prospection pilote les workflows outbound (qualification de leads, génération de mails personnalisés sous validation humaine systématique).
- L'agent conversationnel sert d'interface aux comptables pour interroger la base de connaissance, retrouver un précédent, ou demander une recommandation sur un cas atypique.
Autour de ces agents, une couche de services métier (FastAPI) encapsule les opérations idempotentes : extraction OCR (cascade PyMuPDF / PaddleOCR / MinerU selon la qualité), validation arithmétique, croisement référentiel, génération d'écriture vers Business Central. Ces services ne sont pas des agents. Ce sont des bibliothèques exposées par API, invocables par les agents ou par d'autres services.
Couche 5 : observabilité et gouvernance
L'observabilité est transversale. Elle ne se rajoute pas après coup, elle se conçoit avec l'architecture. Trois outils la portent.
Loki + Grafana ingèrent les logs structurés. Chaque service émet un log JSON pour chaque opération significative : requête reçue, décision prise, appel sortant, résultat, temps de traitement. Les logs sont indexés par service, par client, par type d'opération. Une recherche dans Grafana permet de reconstituer la trace complète d'un document en quelques secondes.
Prometheus collecte les métriques techniques. Latence par étape, taux d'échec service, queue depth, charge GPU, taux d'utilisation cache. Les métriques alimentent les dashboards et les règles d'alerte. Une queue qui se remplit, un service qui dérive, un GPU qui sature, déclenchent une notification opérationnelle.
Langfuse capte spécifiquement les traces LLM. Pour chaque appel à un modèle, Langfuse enregistre le prompt complet, la réponse, les tokens consommés, le coût estimé, le score de qualité (quand applicable), et les métadonnées de routage. Cette spécialisation est précieuse parce que les métriques LLM ne se résument pas aux métriques techniques classiques. Suivre un drift de qualité, par exemple, exige de croiser score de confiance, taux d'escalade et feedback humain. Langfuse le permet.
À ces trois outils s'ajoute GlitchTip pour le suivi des erreurs applicatives (équivalent open source de Sentry, déployé en local).
La gouvernance est l'autre face de cette transversalité. Elle pose les règles : qui peut accéder à quoi, quelles données peuvent quitter le périmètre et dans quelles conditions, comment se fait l'effacement, comment se fait la revue. Cette couche est traitée en profondeur dans l'article #6.
Comment ces couches travaillent ensemble : un exemple
Pour rendre l'ensemble concret, suivons une facture fournisseur reçue par email.
Le connecteur email reçoit le message, identifie la pièce jointe, et la dépose dans MinIO. Un événement « document reçu » est émis sur le bus Redis Streams. L'agent documentaire le consomme. Il charge son contexte (le document, l'historique du fournisseur dans Supabase, les patterns dans Qdrant), enchaîne la cascade OCR (services FastAPI), demande une extraction d'entités (qui passe par la couche modèles, route locale Qwen3 par défaut), valide arithmétiquement le résultat, calcule un score de confiance composite. Si le score dépasse le seuil, l'agent demande à l'agent comptable de proposer une écriture. L'agent comptable interroge Neo4j pour le contexte client, génère la proposition, et la dépose dans la queue de validation humaine. Toutes les étapes sont journalisées dans Loki. Les métriques sont remontées à Prometheus. Les appels LLM sont tracés dans Langfuse.
Si le score de confiance ne dépasse pas le seuil, l'agent documentaire prépare un dossier d'escalade : extrait OCR brut, hypothèses formulées, points d'incertitude. Le dossier va à un comptable humain qui tranche, et sa décision enrichit la base d'apprentissage.
Aucune donnée ne sort du périmètre Synergix dans ce parcours. Si à un moment la complexité justifiait un appel à gpt-4o (typiquement, un document multilingue avec un libellé inhabituel), le pipeline de masquage GLiNER (article #6) interviendrait avant tout appel sortant.
Ce que la stack permet, ce qu'elle exige
Cette stack permet trois choses qu'une SaaS clé en main ne permet pas. Elle nous donne la maîtrise opérationnelle de la circulation des données. Elle nous donne un coût marginal prévisible, indépendant du volume de tokens. Elle nous donne une capacité d'amélioration continue : chaque incident, chaque drift, chaque retour humain enrichit notre compréhension du système et alimente les décisions suivantes.
Elle exige en contrepartie une discipline opérationnelle qu'il serait malhonnête de minimiser. Il faut surveiller la charge GPU, mettre à jour les modèles, calibrer les seuils, investiguer les drifts, gérer les sauvegardes, tester les bascules. Il faut aussi des compétences que le marché ne fournit pas en abondance : ingénieurs IA, MLOps, data engineering. Cette discipline n'est pas un coût caché. C'est un actif que nous accumulons.
Ce qu'on traite dans les prochains articles
Les articles suivants approfondissent les couches de cette stack. L'article #6 décrit la couche invisible : comment nous protégeons le secret professionnel face aux LLM, et comment se construit concrètement un pipeline de masquage de PII opérationnel. L'article #7 propose un cadre de décision concret : quand utiliser un workflow déterministe, quand un RAG, quand un agent. L'article #8 suit un document de bout en bout, depuis sa réception jusqu'à l'écriture comptable validée. L'article #9 plonge dans l'évaluation continue des agents : métriques, drift, calibration.
Le panorama est posé. La suite est une plongée par couche.