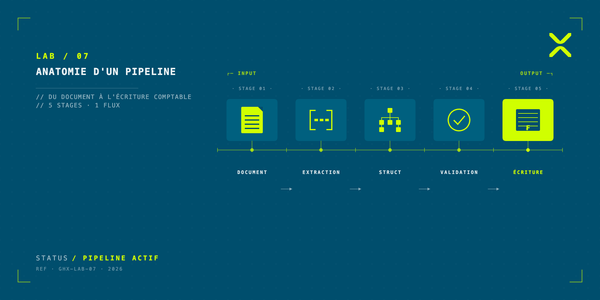
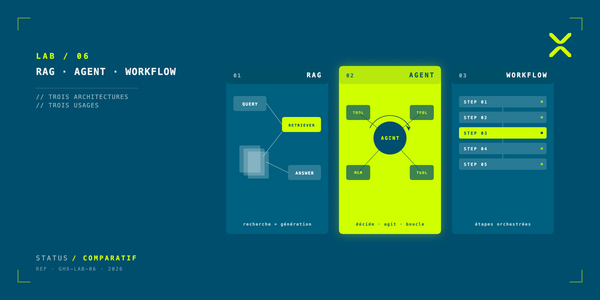
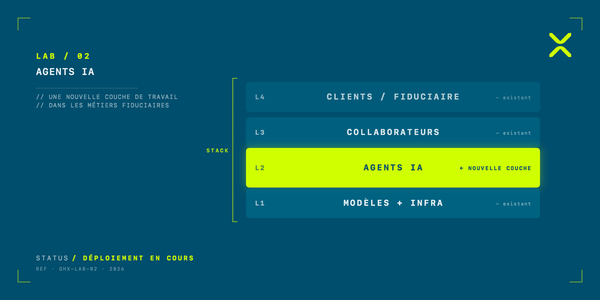
Pourquoi nous avons construit une infrastructure IA en interne

Le récit d'un arbitrage, pourquoi Synergix a choisi de construire sa propre stack IA plutôt que de souscrire à une solution clé en main.
Une infrastructure IA fiduciaire interne désigne l'ensemble des modèles de langage, bases de connaissance, pipelines de traitement et garde-fous de gouvernance déployés et opérés à l'intérieur du périmètre d'un cabinet, sans dépendance fonctionnelle à un service tiers pour les opérations critiques.
La question qu'on me pose tout le temps
Quand quelqu'un découvre l'infrastructure IA de Synergix, plusieurs agents spécialisés en production orchestrés par notre orchestrateur interne, des modèles de langage open-source hébergés sur notre infrastructure en Suisse, une cascade OCR multi-modèles qui digère des centaines de pages par jour, des graphes de connaissance par client, un pipeline de masquage des données personnelles avant tout appel à un modèle externe, la première question est presque toujours la même : « Pourquoi avoir construit tout ça en interne ? Vous auriez pu prendre ChatGPT Enterprise ou Microsoft Copilot et passer à autre chose. »
C'est une question légitime. Et elle mérite une réponse précise, parce que la réponse explique tout le reste : la stack qu'on a choisie, les arbitrages qu'on a faits, et les contraintes qu'on a acceptées.
Le métier fiduciaire ne ressemble pas aux autres métiers
Pour comprendre l'arbitrage, il faut commencer par le métier. La comptabilité fiduciaire en Suisse opère sous trois contraintes qui rendent le « passons à ChatGPT » beaucoup moins évident qu'il n'en a l'air.
Le devoir de discrétion. Le mandat fiduciaire engage une obligation de fidélité et de diligence (Art 398 CO) qui couvre toute donnée confiée par le client. Ce devoir, renforcé par les clauses de confidentialité signées avec chaque mandant, s'applique à tout ce qui transite par nos systèmes. La nLPD ajoute une responsabilité de sous-traitant qui interdit le transfert ou le traitement d'une donnée client sans encadrement explicite. Une donnée qui sort de notre périmètre sans justification fonctionnelle et sans cadre contractuel n'est pas une mauvaise pratique : c'est un manquement contractuel et potentiellement une violation nLPD.
La nLPD et le RGPD. La loi suisse sur la protection des données (en vigueur depuis 2023) et le RGPD pour nos clients européens posent un cadre exigeant : finalité explicite, transparence, portabilité, droit à l'effacement, transferts internationaux encadrés. Ces obligations s'appliquent à chaque circulation de donnée, y compris vers un fournisseur de modèle de langage.
Les exigences de traçabilité et nos clients régulés. L'Art 958f CO impose à toute entreprise un archivage rigoureux de ses documents comptables sur dix ans, avec garantie d'intégrité et de restitution. Cette obligation pèse sur nous comme sur nos clients. Plusieurs de nos clients sont par ailleurs régulés par la FINMA, et même sans être nous-mêmes sous régulation directe, nous devons concevoir notre traitement de la donnée pour répondre aux exigences de gouvernance des sous-traitants que ces régulations imposent à nos clients : traçabilité, isolation, possibilité d'audit. Tout ce qui transite par un agent doit pouvoir être journalisé, retrouvé, restauré.
À ces trois contraintes s'ajoute une quatrième, plus diffuse mais tout aussi structurante : la confiance. Un dirigeant nous confie ses comptes, ses bilans, parfois ses projections stratégiques. Si on lui dit « ne vous inquiétez pas, vos données sont chez OpenAI mais ils ont signé un accord de zero-data-retention », on reçoit rarement un sourire détendu en retour. La confiance ne se délègue pas par contrat. Elle se gagne par démonstration.
Trois options sur la table
Quand nous avons décidé d'industrialiser notre usage de l'IA, trois options se présentaient.
Option 1. La SaaS clé en main. ChatGPT Enterprise, Microsoft Copilot pour Microsoft 365, Anthropic Claude for Work. Souscription mensuelle par utilisateur, déploiement immédiat, qualité élevée des modèles. Coût d'entrée faible, time-to-value de quelques semaines.
Le problème. Le contrôle. Sur un Copilot Microsoft, nous décidons qui peut accéder, à quoi, mais nous ne décidons ni où vit la donnée, ni quel modèle la traite, ni comment elle est journalisée côté fournisseur. Les conditions zero-data-retention sont des engagements contractuels qui peuvent évoluer, et qui ne nous donnent pas la maîtrise opérationnelle de la chaîne. Pour un chatbot qui aide à reformuler un email interne, c'est acceptable. Pour un agent qui lit des bilans clients et propose des écritures comptables, beaucoup moins.
Option 2. L'intégration légère. Brancher un modèle commercial (OpenAI, Anthropic) à nos propres systèmes via API, en construisant une fine couche d'orchestration. Le modèle reste hébergé chez le fournisseur, mais nous reprenons la main sur les flux, les prompts, le stockage des résultats.
Le problème. C'est le pire des deux mondes pour un usage massif. On paye au token un usage qui devient rapidement coûteux à l'échelle d'une fiduciaire (des dizaines de milliers de requêtes mensuelles sur l'OCR, l'extraction, la classification, la recherche). On expose nos données sensibles à un fournisseur sur lequel on n'a pas de prise opérationnelle. Et on construit malgré tout une couche d'intégration substantielle, sans en récupérer les bénéfices stratégiques.
Option 3. L'infrastructure interne. Servir les modèles nous-mêmes (sur GPU loués ou possédés), construire notre propre stack de données, nos propres agents, notre propre observabilité. Investissement initial significatif, courbe d'apprentissage longue.
Les bénéfices. La donnée client ne quitte plus notre périmètre par défaut, seulement par exception encadrée. Le coût marginal devient prévisible (loyer GPU constant) plutôt que variable (token-based). Et surtout : on apprend. On découvre ce qui marche, ce qui casse, ce qui mérite d'être abandonné. Cet apprentissage est lui-même un actif pour les années qui viennent.
Ce que nous avons tranché, et pourquoi
Nous avons retenu l'option 3, avec une nuance importante : ce n'est pas un fanatisme de l'intérieur. Nous gardons un usage encadré des modèles cloud (OpenAI gpt-4o) pour les cas où la qualité de raisonnement justifie la circulation des données, mais cet usage passe systématiquement par notre pipeline de masquage et notre matrice de carve-outs, ratifiée au niveau direction. Nous y reviendrons en détail dans un prochain article du Lab.
Trois raisons ont pesé dans la décision.
Souveraineté de la donnée. C'est le critère qui élimine l'option 1 et fragilise l'option 2. Une fiduciaire qui ne peut pas démontrer où vivent les données de ses clients perd la conversation avant de l'avoir commencée. Nous voulions être en mesure de répondre à un dirigeant, à un auditeur, à un régulateur : « la donnée est dans notre stack, sur notre infrastructure, traitée par nos modèles, journalisée par nos systèmes, accessible uniquement à nos collaborateurs autorisés. » Cette phrase n'a pas de prix.
Coût marginal maîtrisé. À volume modéré (quelques milliers de requêtes par mois), un appel API cloud est moins cher qu'une infrastructure GPU dédiée. À l'échelle où nous opérons aujourd'hui, dizaines de milliers de requêtes mensuelles, qui croissent à chaque semestre, l'arithmétique s'inverse. Nous payons un coût d'infrastructure raisonnablement stable et nous l'amortissons sur un volume qui croît. Le coût par requête devient marginal, là où une facturation au token reste une charge opérationnelle non plafonnée.
Apprentissage stratégique. Construire une infrastructure interne, c'est se donner les moyens de comprendre ce qu'on fait. On ne déploie pas des agents sur lesquels on n'a aucune visibilité. On ne pilote pas une dérive de modèle qu'on ne mesure pas. On ne corrige pas un comportement aberrant qu'on ne peut pas reproduire. Cette compréhension fine de notre stack est, à terme, un avantage plus durable que le choix d'un fournisseur particulier.
Ce que nous avons accepté en contrepartie
Une décision de cette ampleur ne se prend pas sans assumer ses contreparties. Il serait malhonnête de ne raconter que les bénéfices.
Un investissement initial significatif. Construire une infrastructure IA en interne demande des compétences pointues (ingénieurs IA, MLOps, data engineering) et du matériel (GPU, stockage performant, réseau). Ce n'est pas un investissement amorti en un trimestre. C'est un investissement amorti sur plusieurs années, qui ne se justifie que si l'ambition est durable.
Une courbe d'apprentissage longue. Pendant les premiers mois, nous avons fait des erreurs qu'un fournisseur clé en main nous aurait épargnées : choix de modèles inadaptés au triptyque français-allemand-anglais simultané, configurations vLLM mal calibrées, pipelines OCR qui plafonnaient sur les scans de mauvaise qualité. Chaque erreur nous a coûté du temps. Chaque erreur nous a aussi appris quelque chose qu'aucun fournisseur n'aurait pu nous transmettre.
Une responsabilité opérationnelle entière. Quand un agent dérape, ce n'est pas un fournisseur qui doit s'expliquer. C'est nous. Quand une mise à jour de modèle change un comportement, c'est nous qui le détectons, le diagnostiquons, le corrigeons. Cette responsabilité est lourde. Elle est aussi clarifiante : on sait à qui s'adresser, on sait quoi corriger, on sait quoi journaliser.
Une exigence de discipline. Une infrastructure IA interne n'est jamais finie. Il y a toujours un modèle à mettre à jour, une vulnérabilité à corriger, un drift à surveiller, une régression à investiguer. Cette exigence de discipline, nous la traitons comme une exigence de premier plan, pas comme une formalité tardive.
Ce que nous n'avions pas vu venir
Avec un an de recul, plusieurs apprentissages méritent d'être nommés.
Le coût caché de la conformité. Construire la couche technique est une chose. Construire la couche de gouvernance qui rend cette technique acceptable d'un point de vue réglementaire en est une autre, souvent sous-estimée. Le pipeline de masquage des données personnelles, la matrice de carve-outs, la procédure d'effacement multi-stores conforme RGPD/nLPD, la politique de rétention auditable : ces composants représentent une part significative du travail. Ils n'apparaissent dans aucun benchmark de performance. Ils sont pourtant la condition sine qua non d'une exploitation professionnelle.
La valeur de l'observabilité. Au début, nous avons sous-investi dans l'observabilité, pensant qu'elle suivrait naturellement. Erreur. Sans Loki, Grafana, Prometheus et Langfuse correctement instrumentés, on ne sait pas pourquoi un agent se comporte différemment de la semaine précédente. On découvre les problèmes par leurs conséquences, pas par les signaux. Aujourd'hui, l'observabilité est traitée comme un composant de premier rang, pas comme un complément.
L'effet d'apprentissage transverse. Les compétences que nos équipes développent autour de l'IA, pensée par flux, calibration de modèles, raisonnement sur les coûts variables, ergonomie de la supervision humaine, irriguent d'autres parties du métier. Le comptable qui a appris à superviser un agent comprend mieux ses propres processus. L'ingénieur qui a stabilisé un pipeline pense différemment l'architecture de tous les autres. Cet effet n'était pas dans le business case initial. Il pèse aujourd'hui dans le bilan.
Pour qui cet arbitrage a-t-il du sens ?
Je veux être précis ici, parce que la réponse n'est pas universelle.
Construire une infrastructure IA en interne a du sens si trois conditions sont réunies. Premièrement, un volume de traitement suffisamment élevé pour amortir l'investissement (en dessous de quelques milliers de requêtes mensuelles, l'option 2 reste plus rationnelle). Deuxièmement, des contraintes de souveraineté de donnée qui rendent l'option 1 inapplicable de fait, régulation, secret professionnel, attentes clients structurelles. Troisièmement, une volonté stratégique d'apprendre, et un horizon d'investissement de plusieurs années.
Pour beaucoup d'organisations, ces trois conditions ne sont pas réunies. Elles ont raison de prendre une SaaS clé en main, de l'utiliser sérieusement, et de concentrer leurs efforts ailleurs.
Pour Synergix, elles l'étaient. Le métier fiduciaire imposait la souveraineté. Le volume était au rendez-vous. L'horizon stratégique était posé.
Ce que cette décision a permis
Cette décision, prise au printemps 2025, a permis ce que vous pouvez observer aujourd'hui dans nos opérations : des modèles de langage open-source hébergés sur notre propre infrastructure en Suisse, un pipeline OCR multi-modèles qui digère les documents quotidiens avec un taux d'automatisation que nous n'aurions pas obtenu sur étagère, des graphes de connaissance par client qui structurent ce que nos collaborateurs lisent et déduisent, plusieurs agents spécialisés orchestrés par notre orchestrateur interne, le tout sans envoyer la donnée client à un fournisseur tiers par défaut. Une stack que nos équipes comprennent et savent dépanner. Pas une démonstration. Une exploitation.
Le prochain article de cette série décrira comment cette infrastructure est architecturée concrètement, composants, bases de données, flux, orchestration. Pour le moment, l'essentiel tient en une phrase : nous avons construit cette infrastructure parce que le métier que nous exerçons ne nous laissait pas d'autre option satisfaisante.
Et parce qu'il est plus intéressant de comprendre ses outils que de les louer.